Data
Author: Christoph Forster
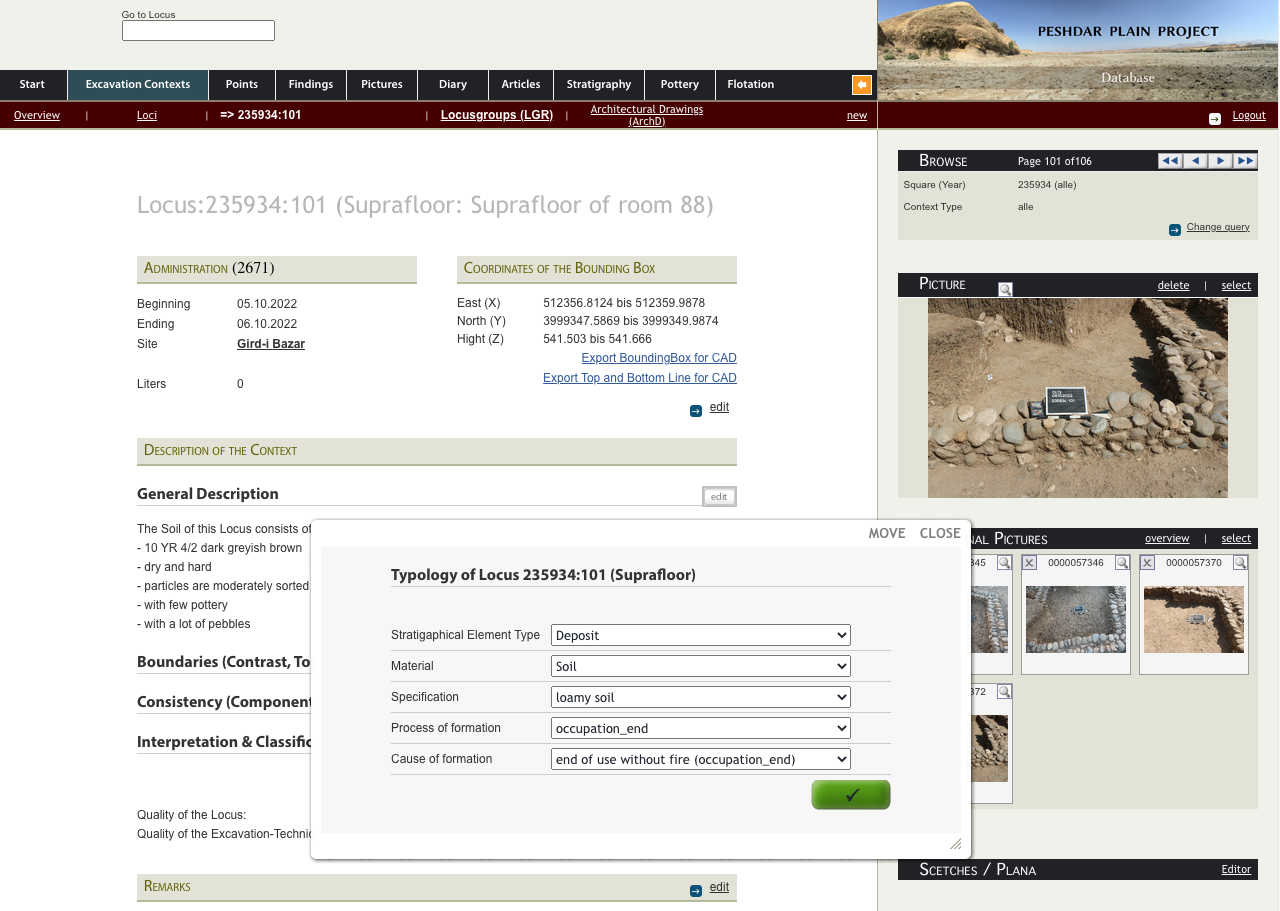
For the documentation of the excavations, the Peshdar Plain Project uses a server-based database that contains all the information on the excavated features and finds, the analyses of the pottery and the flotation samples, and in future also the examinations of the animal bones. The database thus forms the backbone of the work on and with the collected data.
During the excavations, the database runs on a local server in Kurdistan, and during the work phases when no excavations are taking place, it is accessible worldwide on the internet. This is especially important because the Peshdar Plain Project was designed from the beginning to be multi- and interdisciplinary, so that all international project staff can access the data of all other staff members.
For the digital documentation of the excavation, the project uses an adapted database that was originally developed for the archaeological research project "Origin and Development of the Hittite Culture in the Middle Black Sea Region in the Oymaağaç - Vezirköprü, Northern Turkey" and has also been used since 2016 by the Peshdar-Plain-Project - in an already heavily modified form. This has made it possible to replace a lot of basic programming, but the database still has to be constantly adapted to the specific requirements of the excavations in the Dinka settlement complex, new data sets have to be integrated and existing ones visualised and processed for rapid data evaluation.
When expanding the database, we take into account current standardisation efforts such as the recommendations of UNESCO ObjectID and use standards data and controlled vocabularies (such as those of the Getty Art & Architecture Thesaurus - AAT) to keep the data as long-term and internationally connectable as possible. Finally, a large part of the data is prepared for archiving in accordance with the guidelines of the German Research Foundation, transferred to suitable repositories at the WWU Münster and thus published as Open Data.